Apache Flink介绍
大数据处理计算模式
- 批量计算-(batch)
- MapReduce
- Apache Spark
- Hive
- Flink
- Pig
- 流式计算(stream)
- Storm
- Spark Streaming
- Apache Flink
- Samza
- 图计算(graph)
- Giraph(Facebook)
- Graphx(Spark)
- Gelly (Flink)
- 交互计算(interactive)
- Presto
- Impala
- Druid
- Drill
流计算与批计算对比
- 数据实效性
- 数据特征
- 应用场景
- 运行方式
流式计算将成为主流
- 数据处理时延要求越来越高
- 流式处理计算日趋成熟
- 批计算带来的计算和存储成本
- 批计算本身就是一种特殊的流计算,批和流本身就是相辅相成的
使用流计算的场景
- 实时监控:
- 用户行为预警
- 实时报表
- 双11活动直播大屏
- 对外数据产品-生意参谋
- 数据化运营
- 流数据分析
- 实时计算相关指标反馈及时调整决策
- 内容投放
- 实时数据仓库
- 数据实时清洗、归并、结构化
- 数仓的补充和优化
流计算框架和产品
- 第一类-商业级流计算平台
- 开源流式计算框架
为什么是Flink
- 低延迟-毫秒级延迟
- 高吞吐-每秒千万级吞吐
- 准确性-Exactly-once语义
- 易用性-SQL/Table Api/DataStream Api
Apache Flink核心特性
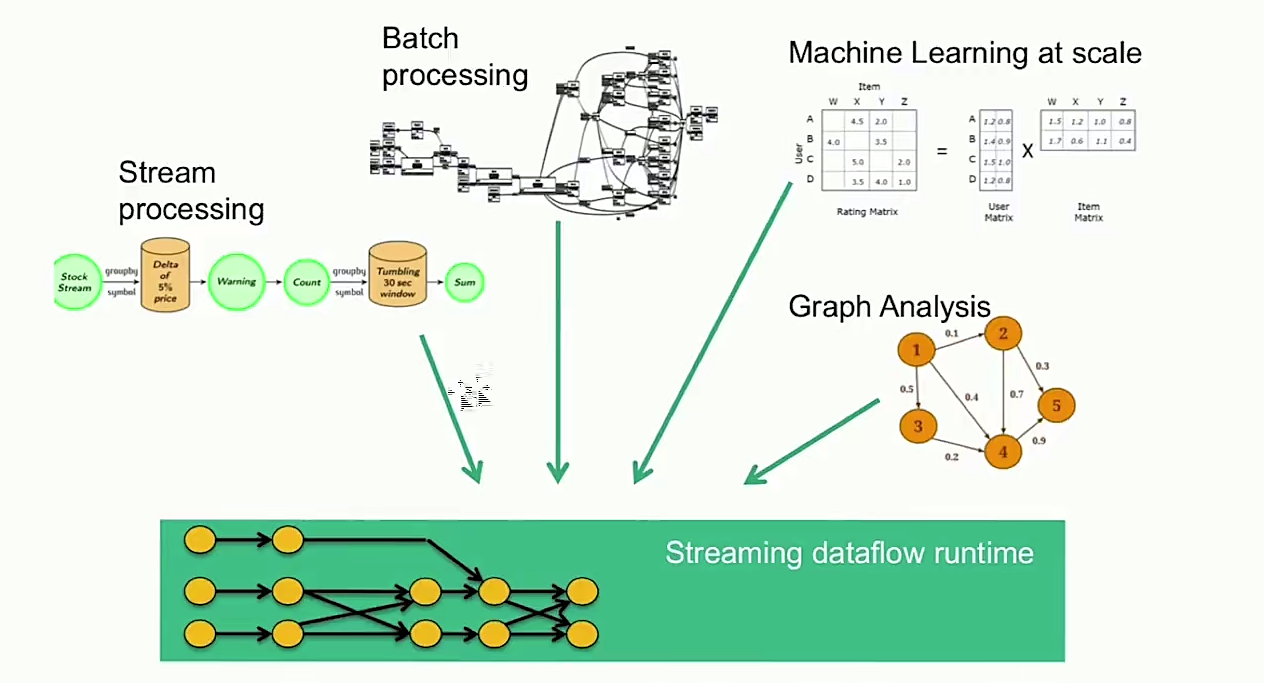
- 统一数据处理组件栈,处理不同类型的数据需求(batch,stream,Machine Learning,graph)
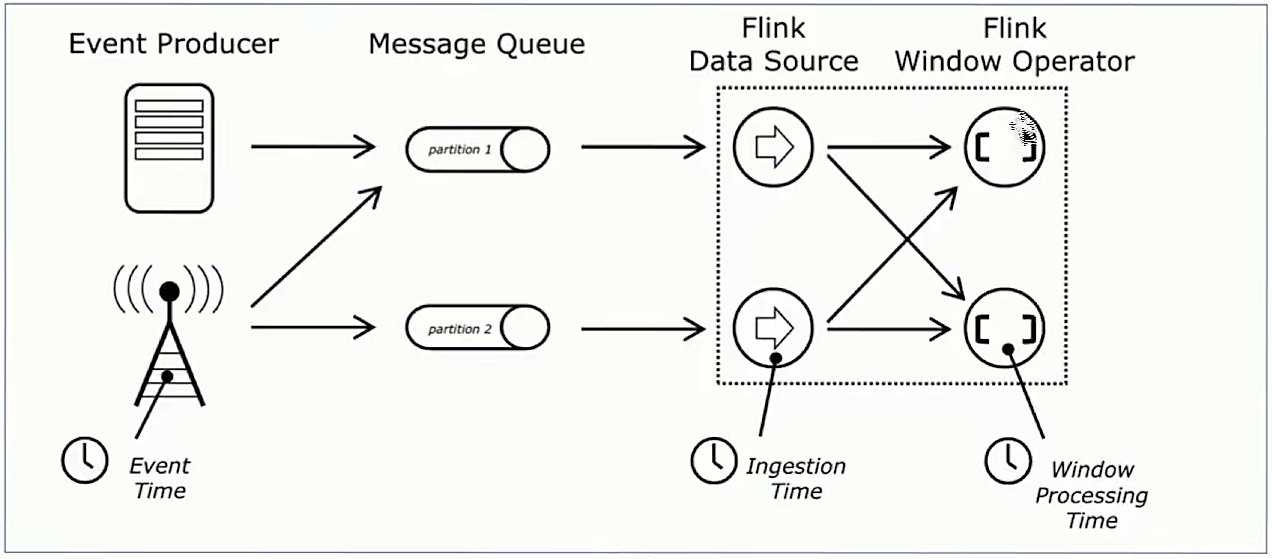
- 支持事件实践,接入时间,处理时间等时间概念
- 基于轻量级分布式快照(snapshot)实现容错
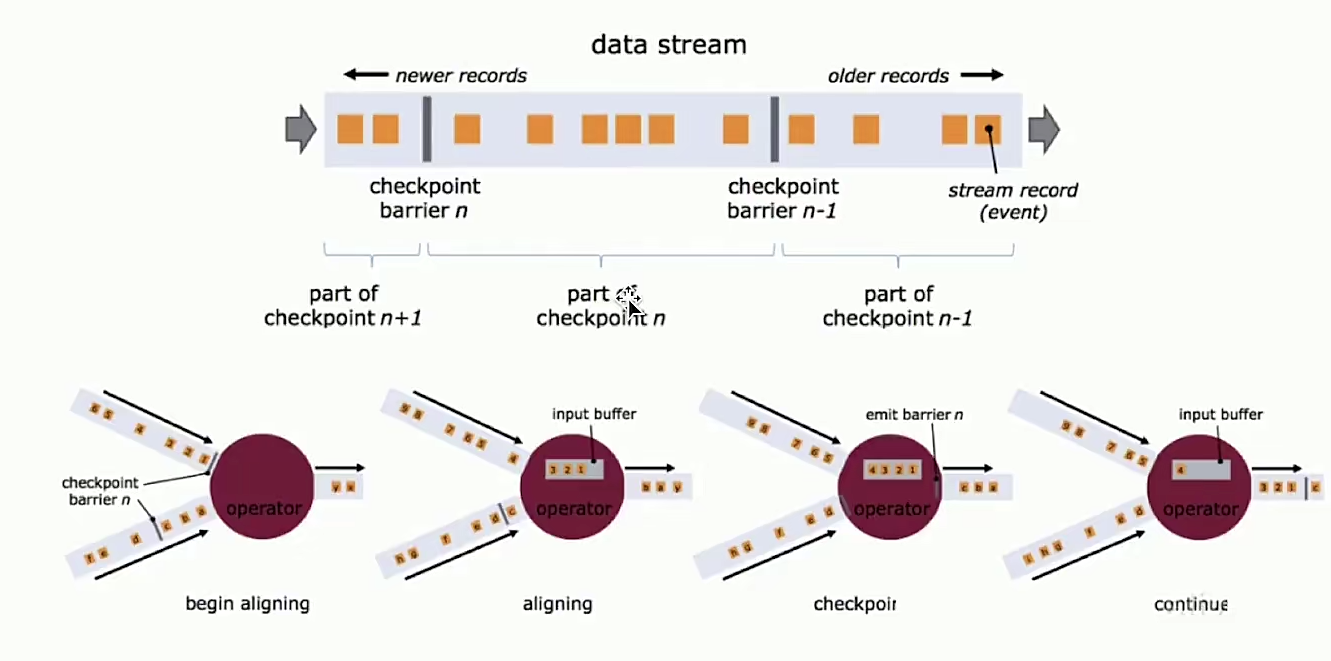
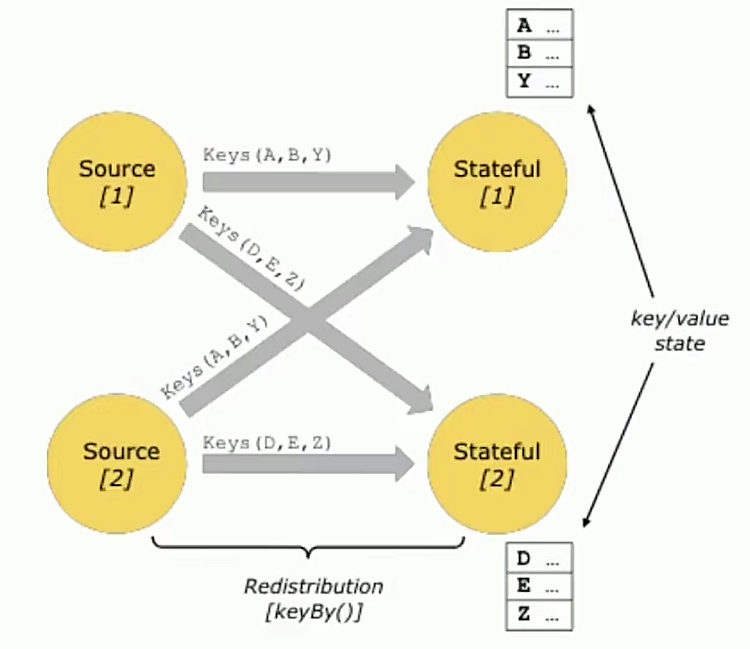
- 支持状态计算、灵活的state-backend(HDFS,内存,RocksDB)
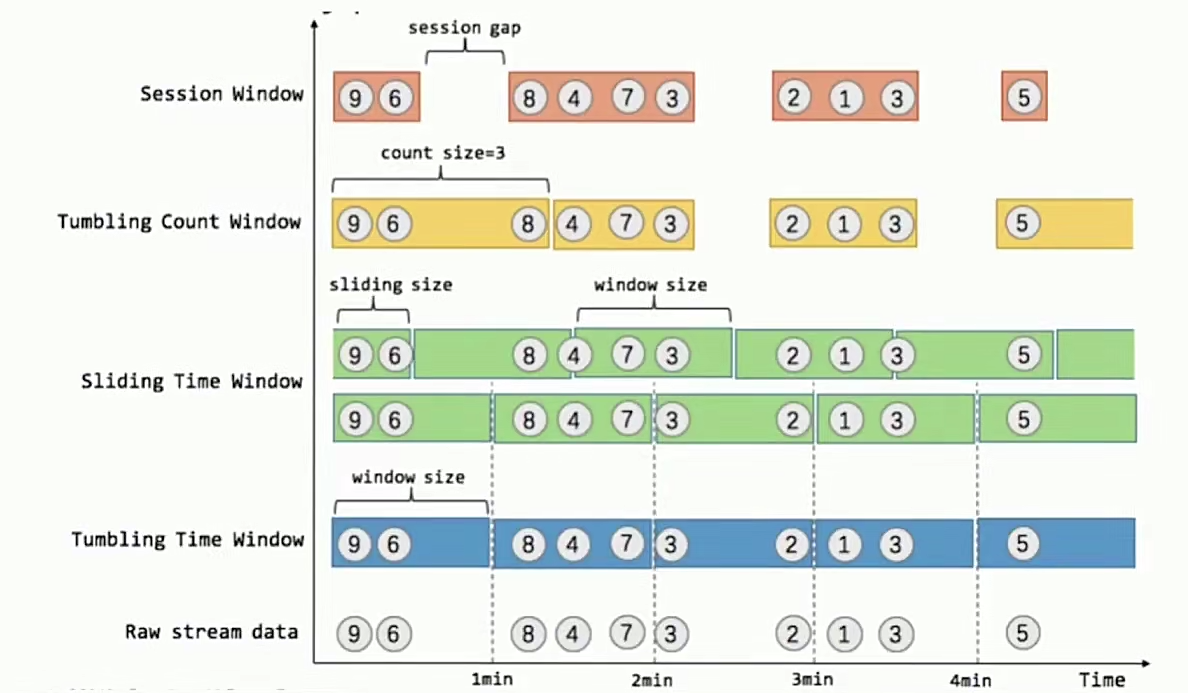
- 支持高度灵活的窗口(Window)操作
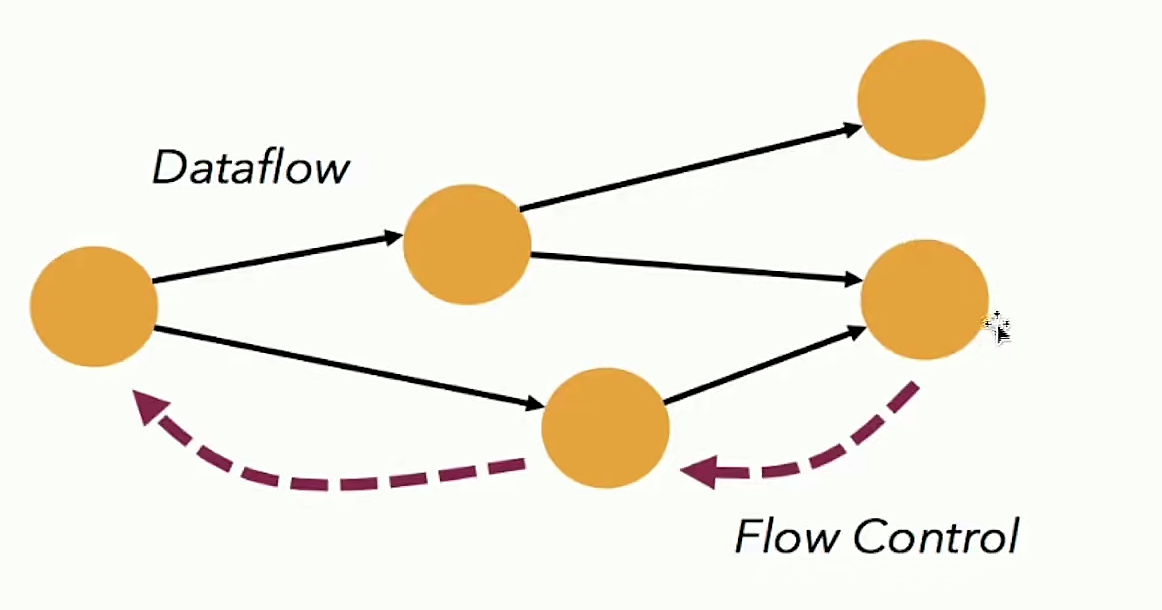
- 带反压的连续流模型
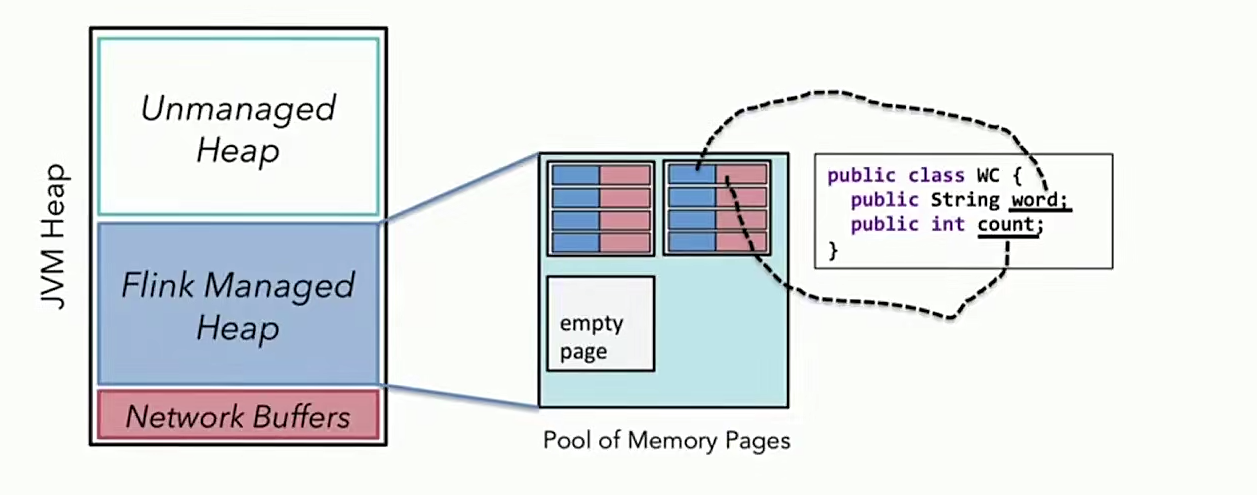
- 基于JVM实现独立的内存管理