分布式流处理模型
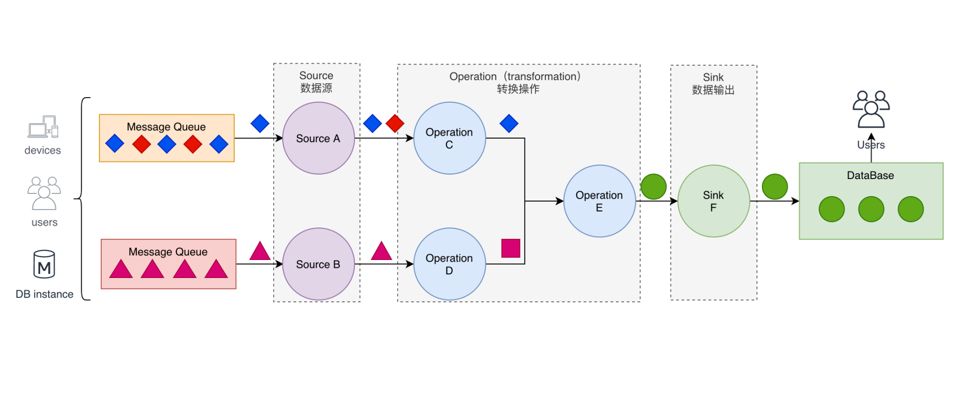
- Source-数据源:
- 如何与外部系统进行打通
- 读取相应消息中间件、socket端口里面数据
- Operation-转换操作:
- 如何把接入的数据,进行相应转化操作,进行filter 或 transform
- 将不同的流进行connect的关联操作,最终转化为一个完整的结果
- Sink-数据输出:
- 通过数据输出sink输出到外围的数据系统中
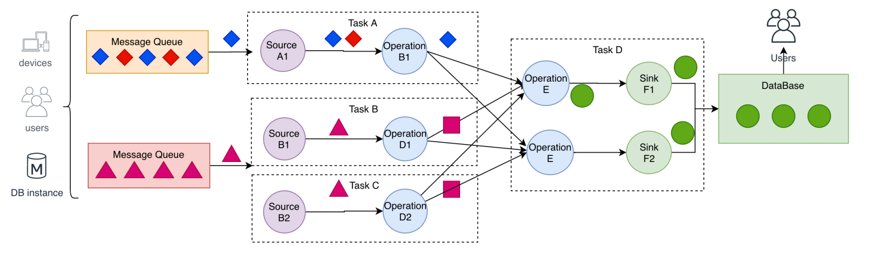
- 数据从上一个 Operation 节点直接 Push 到下一个 Operation 节点。
- 各节点可以分布在不同的 Task 线程中运行,数据在 Operation 之间传递。
- 具有 Shuffle 过程,但是数据不像 MapReduce 模型,Reduce 从 Map 端拉取数据。
- 实现框架有 Apache Storm 和 Apache Flink 以及 Apache Beam。
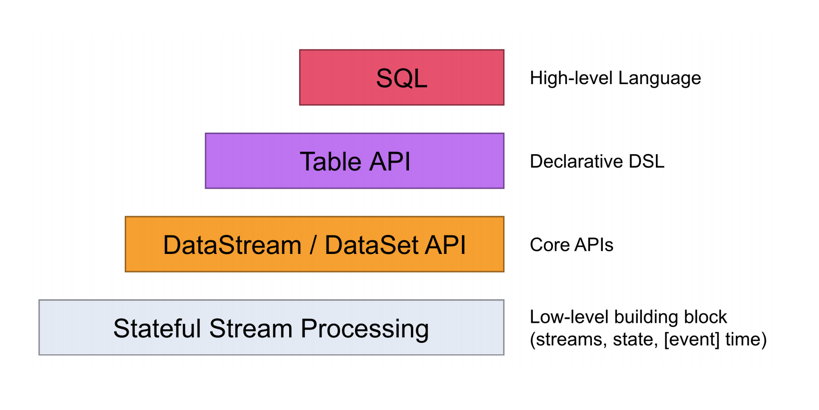
DataStream API介绍
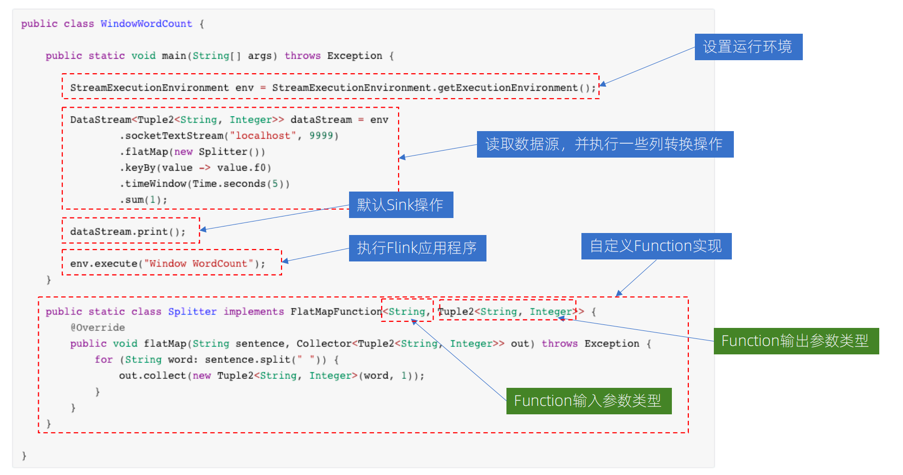
Flink DataStream 程序示例
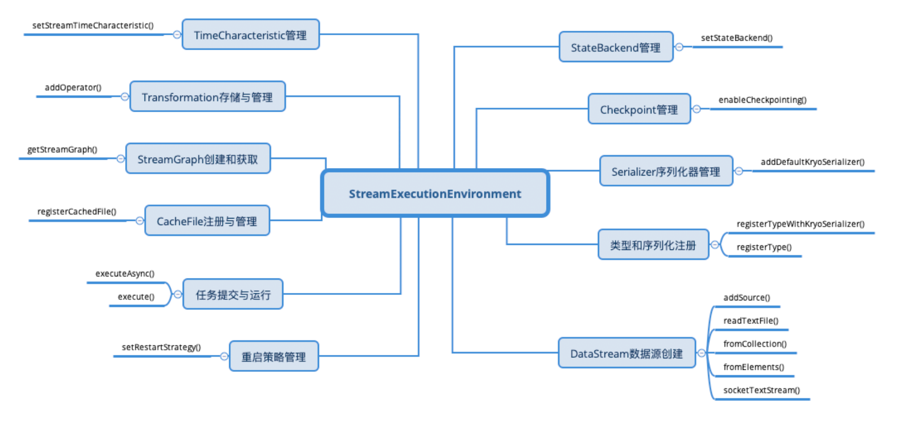
StreamExecutionEnvironment
DataStream数据源
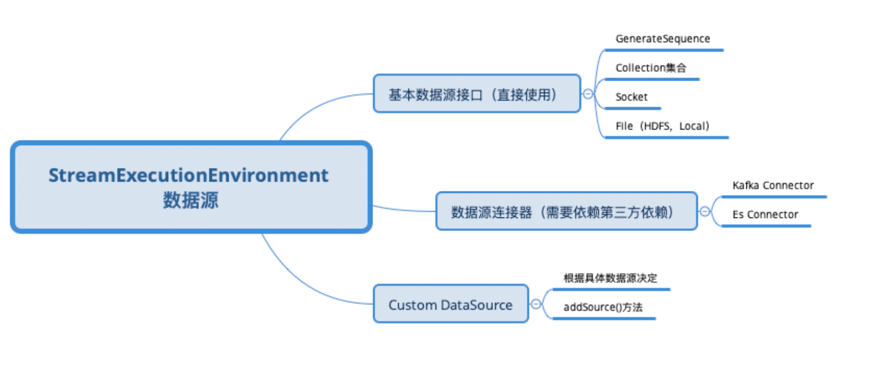
DataStream 基本数据源
// 从给定的数据元素中转换
DataStreamSource<OUT> fromElements(OUT... data)
// 从指定的集合中转换成DataStream
DataStreamSource<OUT> fromCollection(Collection<OUT> data)
// 读取文件并转换
DataStreamSource<OUT> readFile(FileInputFormat<OUT> inputFormat, String filePath)
// 从Socket端口中读取
DataStreamSource<String> socketTextStream(String hostname, int port, String delimiter)
// 直接通过InputFormat创建
DataStreamSource<OUT> createInput(InputFormat<OUT, ?> inputFormat)
// 最终都是通过ExecutionEnvironment创建fromSource()方法转换成DataStreamSource
DataStream 数据源连接器
- Flink 内置 Connector:
- Apache Kafka (source/sink)
- Apache Cassandra (sink)
- Amazon Kinesis Streams (source/sink)
- Elasticsearch (sink)
- Hadoop FileSystem (sink)
- RabbitMQ (source/sink)
- Apache NiFi (source/sink)
- Twitter Streaming API (source)
- Google PubSub (source/sink)
- JDBC (sink)
</br>
- Apache Bahir 项目:
- Apache ActiveMQ (source/sink)
- Apache Flume (sink)
- Redis (sink)
- Akka (sink)
- Netty (source)
DataStream 数据源连接器 - source
<!-- 以 Kafka 连接器为例:-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.11</artifactId>
<version>1.11.0</version>
</dependency>
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "localhost:9092");
properties.setProperty("group.id", "test");
DataStream<String> stream = env.addSource(new FlinkKafkaConsumer<>("topic",new SimpleStringSchema(), properties));
// 指定kafka偏移量
Map<KafkaTopicPartition, Long> specificStartOffsets = new HashMap<>();
specificStartOffsets.put(new KafkaTopicPartition("myTopic", 0), 23L);
specificStartOffsets.put(new KafkaTopicPartition("myTopic", 1), 31L);
specificStartOffsets.put(new KafkaTopicPartition("myTopic", 2), 43L);
myConsumer.setStartFromSpecificOffsets(specificStartOffsets);
DataStream 数据源连接器 - sink
DataStream<String> stream = ...
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "localhost:9092");
FlinkKafkaProducer<String> myProducer = new FlinkKafkaProducer<>(
"my-topic", // target topic
new SimpleStringSchema(), // serialization schema
properties, // producer config
FlinkKafkaProducer.Semantic.EXACTLY_ONCE); // fault-tolerance
stream.addSink(myProducer);
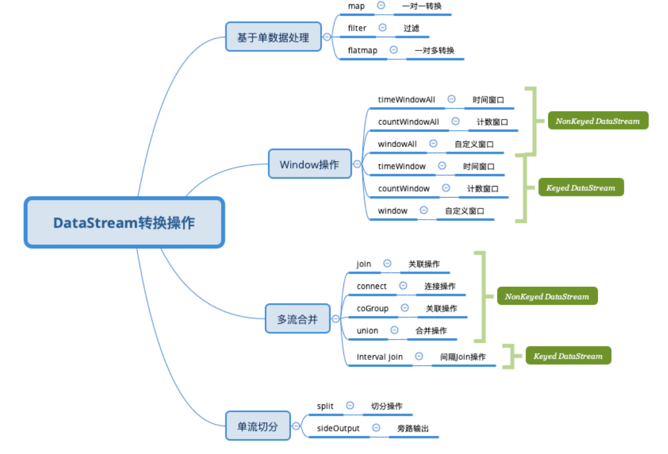
DataStream 主要转换操作
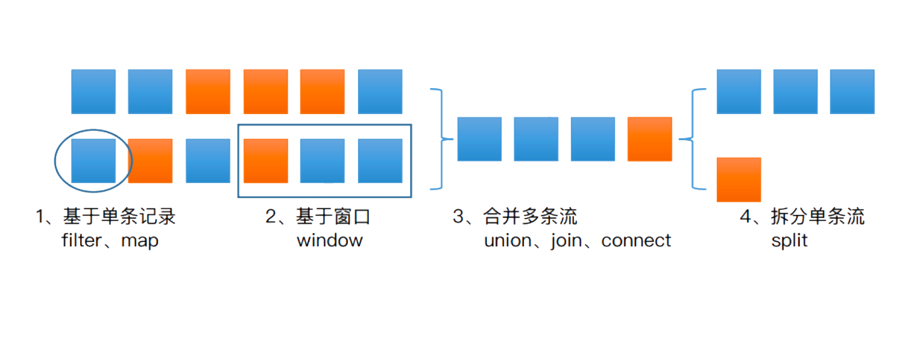
</br>
理解 KeyedStream
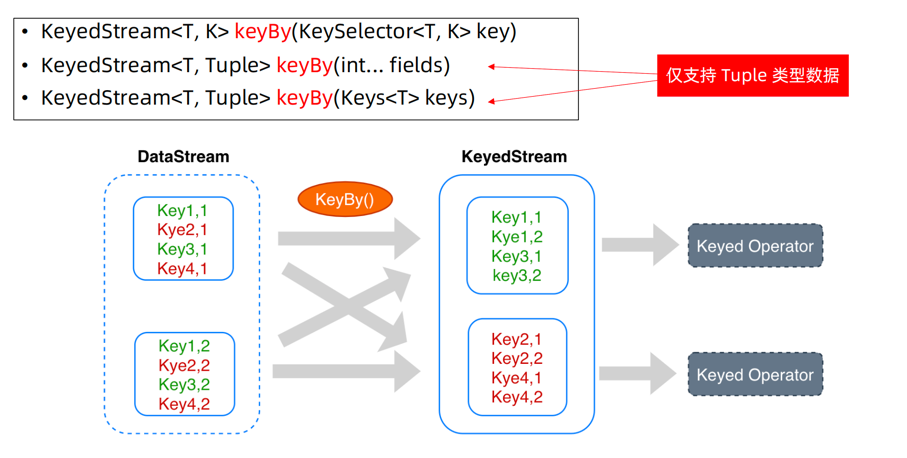
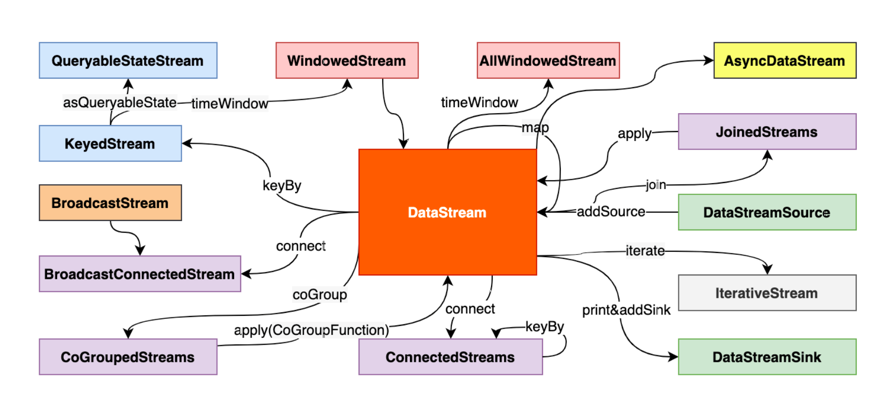
DataStream之间的转换
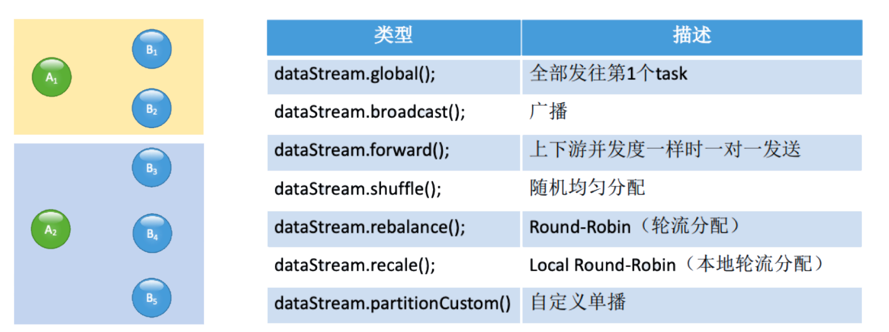
物理分组操作
上下游之间进行分组的过程,进行数据的分发和分配
public DataStream<T> shuffle() {
// ConnectionType 上下游算子进行连接方式
// ShufflePartitioner最终会调用flink底层resultPartition和inputChannel之间连接策略选择
return setConnectionType(new ShufflePartitioner<T>());
}
DataStream Kafka 示例整体流程
public class KafkaExample {
public static void main(String[] args) throws Exception {
// parse input arguments
final ParameterTool parameterTool = ParameterTool.fromArgs(args);
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.getConfig().setRestartStrategy(RestartStrategies.fixedDelayRestart(4, 10000));
env.enableCheckpointing(5000); // create a checkpoint every 5 seconds
env.getConfig().setGlobalJobParameters(parameterTool); // make parameters available in the web interface
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
DataStream<KafkaEvent> input = env
.addSource(
new FlinkKafkaConsumer<>(
parameterTool.getRequired("input-topic"),
new KafkaEventSchema(),
parameterTool.getProperties())
.assignTimestampsAndWatermarks(new CustomWatermarkExtractor()))
.keyBy("word")
.map(new RollingAdditionMapper())
.shuffle();
input.addSink(
new FlinkKafkaProducer<>(
parameterTool.getRequired("output-topic"),
new KeyedSerializationSchemaWrapper<>(new KafkaEventSchema()),
parameterTool.getProperties(),
FlinkKafkaProducer.Semantic.EXACTLY_ONCE));
env.execute("Modern Kafka Example");
}
}